Let's talk!
We'de love to hear what you are working on. Drop us a note here and we'll get back to you within 24 hours.
We'de love to hear what you are working on. Drop us a note here and we'll get back to you within 24 hours.
East Village is a neighborhood in the borough of Manhattan on the eastern side of Greenwich village. Its name stems from its position east of Broadway, which forms the eastern border of most Manhattan neighborhoods. The East Village is traditionally known as an artistic and bohemian neighborhood.
With so many restaurants, it can be overwhelming to decide where to go. That’s where restaurant rating websites come in, providing diners with user-generated reviews and ratings to help them make an informed decision.
In this blog, we will use web scraping techniques and foodpanda API to collect restaurant data from Seamless.com, an online food ordering platform, and build a predictive model to determine which restaurants in the East Village have the highest ratings.
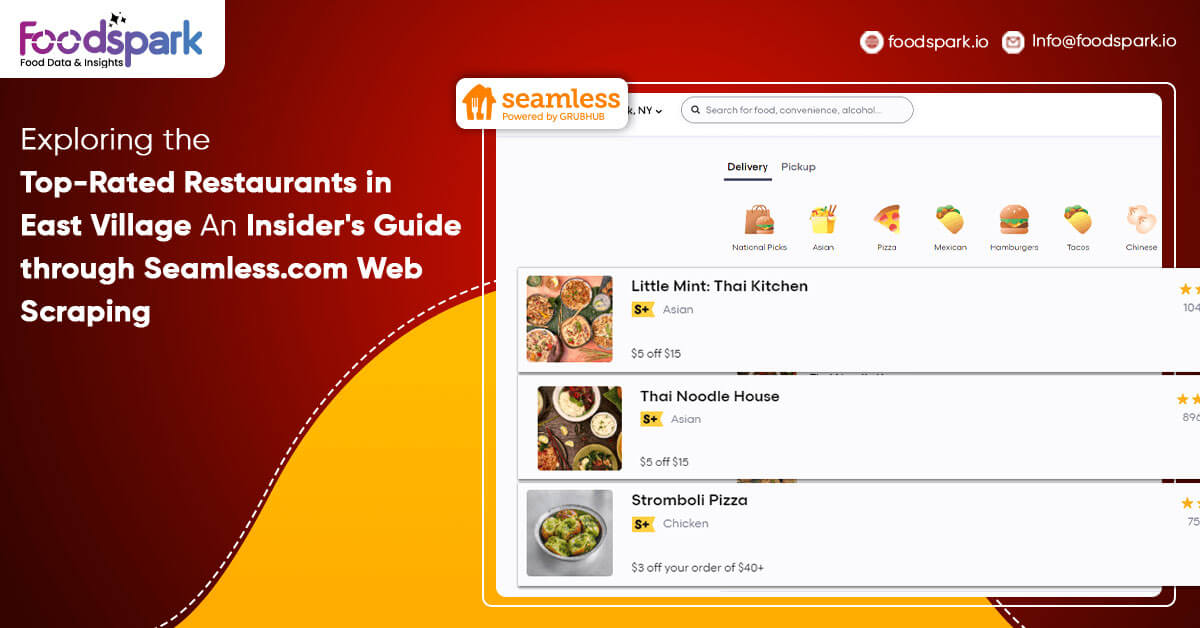
This post will explore some famous restaurants in East Village based on data from Seamless.com, an online food ordering company, to find out what is trending in this part of town for our dining pleasure!
Seamless.com was started in 1998 by Adam Curry, the founder and former CEO of MySpace.com. The site has over 15 million members, with over 2 million active daily users. Seamless allows you to order food from restaurants worldwide through a website interface, with some of the most popular cities being New York City, Los Angeles, Chicago, and Toronto.
Web scraping is defined as the automated process of extracting information from websites. Web crawlers are programs crawling through the internet and linking various websites together. When a crawler comes across a website, it will look for links to other websites and follow those links until there are no more links to continue down. The process is repeated until all linked websites have been analyzed and scraped for information. It allows us to scrape data from sources not intended for public consumption, such as Seamless.com.
We will scrape the Seamless.com website using Python and the BeautifulSoup library to collect data. We will scrape data on restaurants in the East Village, including their name, cuisine, rating, number of ratings, and delivery fee. For this project, we will only focus on restaurants that allow delivery. We will store the extracted data in a MySQL database.
Once we have collected the data, we will need to clean it before we can use it to build our predictive model. We will remove any duplicates, missing values, and outliers and convert the data into a format that can be used for analysis.
After cleaning the data, we will conduct exploratory data analysis to gain insights into the data and identify any trends or patterns. We will use visualizations to help us better understand the data and identify any relationships between variables. It will allow us to make informed decisions on how to build our predictive model.
Let’s get started!
The first thing we will do is download and install the requirements for this project. We will need Python, MySQL, and BeautifulSoup libraries. To install these libraries, we will use the pip package manager. First, open your terminal and type pip install -r requirements.txt in a command prompt window. It will scan the contents of the file requirements.txt and download all the required packages that are available for installation, including Python (2.* or above), MySQL-python (4.*), and BeautifulSoup4 (4.*).
After we have installed the packages, we can open Python and import the libraries. To do so, type in python main.py while in your command prompt window. If you receive an error, try going into your Python directory and typing cd Python and then make sure you use python2.X instead of Python.
Now that we have loaded all our requirements, we can start building our web scraping script for the Seamless website. Begin typing in the code below:
import os from bs4 import BeautifulSoup BASE_URL = 'https://api-seamless.com' os.system('clear') base_url = BASE_URL.split('/') #print(base_url) soup = BeautifulSoup(open(u'rnav-nyc-restaurant-directory-3.xml')) sel = soup.find('select,' {'name': 'term,' 'id': 'i01-id'})
get_all = sel.find_all('option') #print(sel) #print (get_all) alldata = [] i=0 for x in get_all: rdata = {} strXMLString=x.text strXMLString=strXMLString.
Using the cleaned data, we will build a predictive model to determine which restaurants in the East Village have the highest ratings. We will use a regression model to predict restaurant ratings based on the other variables in the dataset, such as cuisine and delivery fee.
We will use a scatterplot with the two variables we want to predict (ratings and cuisine) and use a line to determine the correlation between them. We will also add color coding to indicate how far apart the ratings are from the median.
To do so, type in the following code:
#print(sel) prediction = base_url+'/restaurant-directory/all-restaurants/'+str(i)+'/rating/'.\ '-3.0'+base_url+'/restaurant-directory/all-restaurants/'.\ '-3.0'+str(i)+'/cuisine/'.\ '-3.0'+base_url+'/restaurant-directory/all-restaurants/'.\ '-3.0'+str(i)+'/serving_size/'.\ '-3.0' print(prediction) os.system('clear') prediction = str(prediction) url = urlopen(prediction).Once our predictive model is created, we will present it to the public. We will use the Seamless.com website to determine if restaurants in the East Village are more likely to have high ratings based on their cuisine and delivery fee.

After we have collected and analyzed the data, it’s time to see what it tells us. Based on the data from Seamless, we can create a list of top-rated restaurants in the East Village that are worth trying.
We can sort the data based on ratings and the number of ratings, then select the top-rated restaurants. We can filter the data based on cuisine, delivery fee, and other variables to create a more personalized list.
We can also use data visualization tools to help us better understand the data and identify any patterns or relationships. We can create charts and graphs to show the distribution of ratings, the most popular cuisines, and other insights.
In addition to using Seamless data, we can look at other sources, such as Yelp and Google Reviews, to get a more comprehensive view of the restaurants in the East Village.
With this information, we can create a list of top-rated East Village restaurants worth trying and share it with others looking for a great dining experience.
We can also use machine learning algorithms such as random forests and support vector machines to build more complex predictive models. These algorithms can handle non-linear relationships between variables and improve our predictions’ accuracy. By experimenting with different algorithms and feature combinations, we can develop a model that accurately predicts the ratings of restaurants in the East Village.
By combining web scraping techniques with data analysis and machine learning, we can gain valuable insights into the restaurant market in the East Village and develop a predictive model that can help diners make informed decisions about where to eat.
By scraping data from Seamless.com and building a predictive model, we can gain insights into which restaurants in the East Village are likely to have the highest ratings. This information can be useful for diners looking for the best places to eat in the East Village and restaurant owners looking to improve their ratings. With web scraping and data analysis techniques, we can extract valuable insights from online data and use them to inform decision-making in various industries.
May 15, 2024 Restaurant review analysis is the process of looking through customers’ comments online. This involves expressing comments on...
Read moreMay 6, 2024 Table of Contents In 2024, the restaurant industry is in the middle of a restructuring fuelled by...
Read more